Welcome to multiml’s documentation!
multiml is a prototype framework for developing multi-step machine learnings.
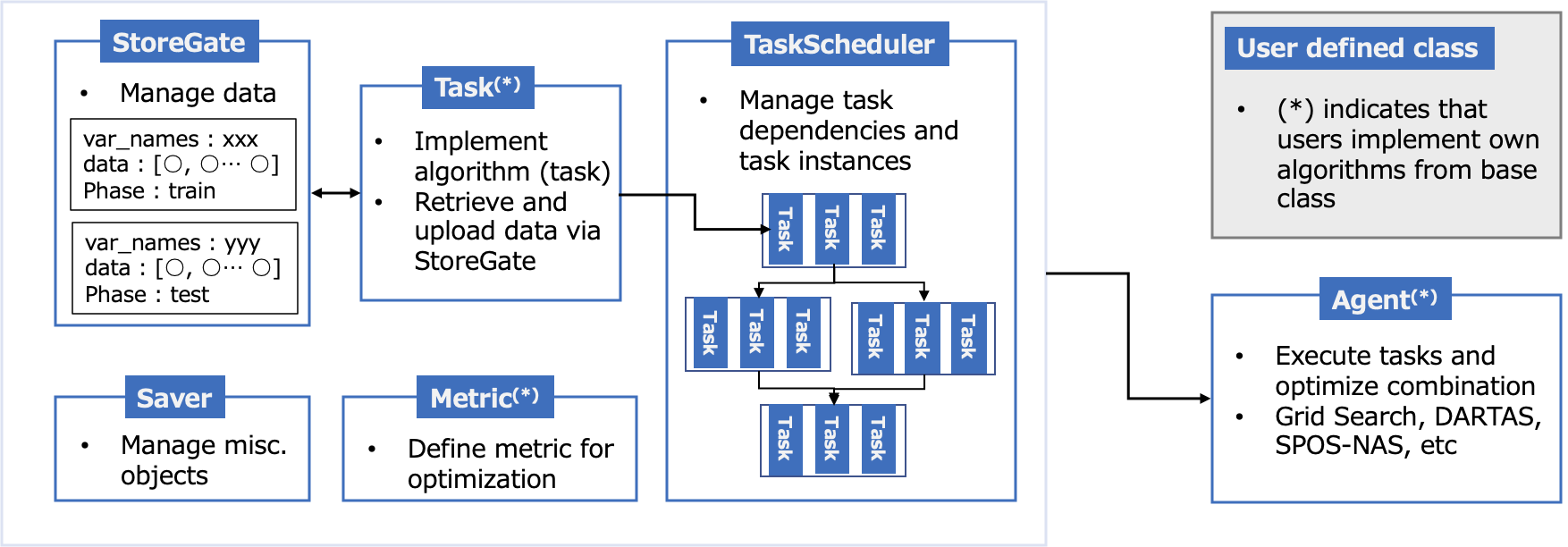
Quick start
This section runs through the APIs to demonstrate Grid Search optimization.
Installation
- Requirements:
CentosOS 7.6+
Python 3.8+
$ git clone https://github.com/UTokyo-ICEPP/multiml.git
$ cd multiml
$ pip install -e .
Preparing data (StoreGate)
import numpy as np
from multiml import StoreGate
storegate = StoreGate(data_id='dataset0')
phase = (0.8, 0.1, 0.1) # fraction of train, valid, test
storegate.add_data(var_names='data', data=np.arange(0, 10), phase=phase)
storegate.add_data(var_names='true', data=np.arange(0, 10), phase=phase)
storegate.compile()
storegate.show_info()
Out:
================================================================================
data_id : dataset0, compiled : True
--------------------------------------------------------------------------------
phase backend var_names var_types total_events var_shape
================================================================================
train numpy data int64 8 (8,)
train numpy true int64 8 (8,)
--------------------------------------------------------------------------------
phase backend var_names var_types total_events var_shape
================================================================================
valid numpy data int64 1 (1,)
valid numpy true int64 1 (1,)
--------------------------------------------------------------------------------
phase backend var_names var_types total_events var_shape
================================================================================
test numpy data int64 1 (1,)
test numpy true int64 1 (1,)
================================================================================
Please see StoreGate tutorial for more details.
Impementing algorithms (Task)
from multiml import logger
from multiml.task import BaseTask
class MyTask(BaseTask):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self._weight = None
def execute(self):
if self._weight is None:
return # no hyperparameter
data = self.storegate['test']['data'][:]
pred = data * self._weight
logger.info(f'pred value = {pred}')
self.storegate['test']['pred'][:] = pred
task = MyTask(storegate=storegate)
task.set_hps(dict(weight=0.5)) # set hyperparameter
task.execute()
Out:
pred value = [4.5]
Please see machine learning task examples.
Registering tasks (TaskScheduler)
from multiml import TaskScheduler
task0 = MyTask()
task1 = MyTask()
hps0 = dict(weight=[0.5, 1.0, 1.5])
steps = [[(task0, hps0)], [(task1, None)]]
task_scheduler = TaskScheduler(steps)
task_scheduler.show_info()
Out:
--------------------------------------------------------------------------------
task_id: step0, DAG: True (parents: [], children: ['step1']):
subtask_id: MyTask, hps: ['weight']
--------------------------------------------------------------------------------
task_id: step1, DAG: True (parents: ['step0'], children: []):
subtask_id: MyTask, hps: []
--------------------------------------------------------------------------------
Optimization (Agent)
from multiml.agent import GridSearchAgent
# minimize Mean Squared Error
agent = GridSearchAgent(storegate=storegate,
task_scheduler=task_scheduler,
metric='MSE')
agent.execute_finalize()
Out:
(1/3) events processed (metric=20.25)
(2/3) events processed (metric=0.0)
(3/3) events processed (metric=20.25)
------------------------------------ Result ------------------------------------
task_id step0 and subtask_id MyTask with:
weight = 1.0
job_id = 1
task_id step1 and subtask_id MyTask with:
job_id = 1
Metric (mse) is 0.0
weight = 1.0 shows the best performance as expected.
API references
- multiml
- multiml.StoreGate
- multiml.TaskScheduler
- multiml.Saver
- multiml.Hyperparameters
- multiml.agent.BaseAgent
- multiml.agent.SequentialAgent
- multiml.agent.RandomSearchAgent
- multiml.agent.GridSearchAgent
- multiml.task.BaseTask
- multiml.task.MLBaseTask
- multiml.task.pytorch.PytorchBaseTask
- multiml.task.keras.KerasBaseTask
- multiml.logger
- multiml.const